Formally verified CRUD
A couple of weeks ago, I published Lean-ing into Software Engineering in which I hypothesized that the combination of the Lean Programming Language and AI-assisted coding meant that we were very close to the point where formal verification was realistic for everyday software engineering.
Since then I've become convinced that we're not close: we're already there.
In this article, I'm going to show a web application implemented in Lean. As you'll see, it's no more difficult to create a web app this way than it would be in Node, Rails, or any other popular stack. But, crucially, by using Lean we can make hard, mathematically guaranteed statements about our app's behaviour. We can prove (not demonstrate through testing, but mathematically prove), for example, that certain types of XSS vulnerability aren't present.
tl;dr
Writing a webapp in Lean is just as easy as in any popular framework, but by doing so we get some very valuable benefits:
- Many common errors are impossible: they will be caught immediately at compile time (or even earlier) with no need to write tests.
- Important invariants can be mathematically proven to hold, completely eliminating some classes of both bugs and security vulnerabilities.
Here is an implementation of the popular TodoMVC web application in Lean, and here is a minimal Lean webapp.
A minimal Lean webapp
I'm going to dive straight in and show a minimal but complete Lean webapp:
imports ...
import Std.Http
import Html
import Routing
open Std Async
open Std Http Server
open Html
open Routing
routeTable! App
[ index := "/",
greet := "/greet/:name:String" ]
def homePage :=
document [
head [ title "Lean Webapp" ],
body [
h1 [ "Welcome to lean-webapp" ],
p [ "A minimal example webapp in Lean." ],
p [ a { href := App.links.greet "world" } [ "Say hello" ] ],
]
]
def greetPage (name : String) :=
document [
head [ title s!"Hello, {name}!" ],
body [
h1 [ s!"Hello, {name}!" ],
p [ a { href := App.links.index } [ "Back home" ] ],
]
]
def app := [
.get App.patterns.index (fun _request => Response.ok.html homePage),
.get App.patterns.greet (fun name _request => Response.ok.html (greetPage name))
] |> toHandler
def main := Async.block do
let addr := .v4 ⟨.ofParts 127 0 0 1, 0⟩
let server ← serve addr app
IO.println s!"Listening on http://{server.localAddr.get!}"
server.waitShutdown
It's immediately obvious what this app does and how it works, even if you don't have any Lean experience. The complete project is available here.
Typesafe HTML
Let's see some of the benefits that we gain. Firstly, the DSL that we're using to generate HTML enforces correct HTML structure. So if (say) I change one of the paragraphs in homePage to contain a <div>, I immediately get an error in the IDE (no need to compile, I see this immediately after I make the change):
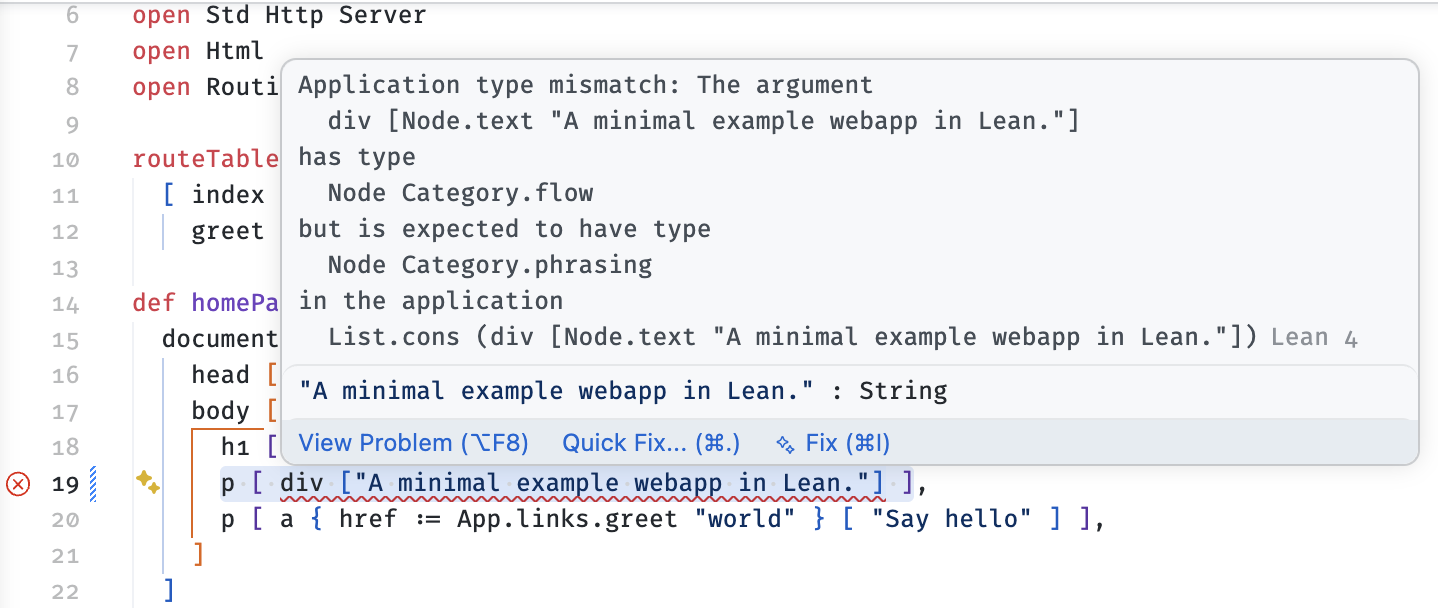
HTML does not allow a <div> to appear within a <p>, and the error explains exactly why: paragraphs expect phrasing content (which doesn't include <div>), not flow content. Lean's type system tells us this immediately in the IDE: no need to compile, no need to run any tests or validate generated HTML.
Typesafe Routing
Here's another example: let's imagine that we change the type of the parameter passed to /greet from String to Nat (Nat is Lean's natural number type).
routeTable! App
[ index := "/",
greet := "/greet/:name:Nat" ]
If I do that, then I immediately see the following error in the IDE:
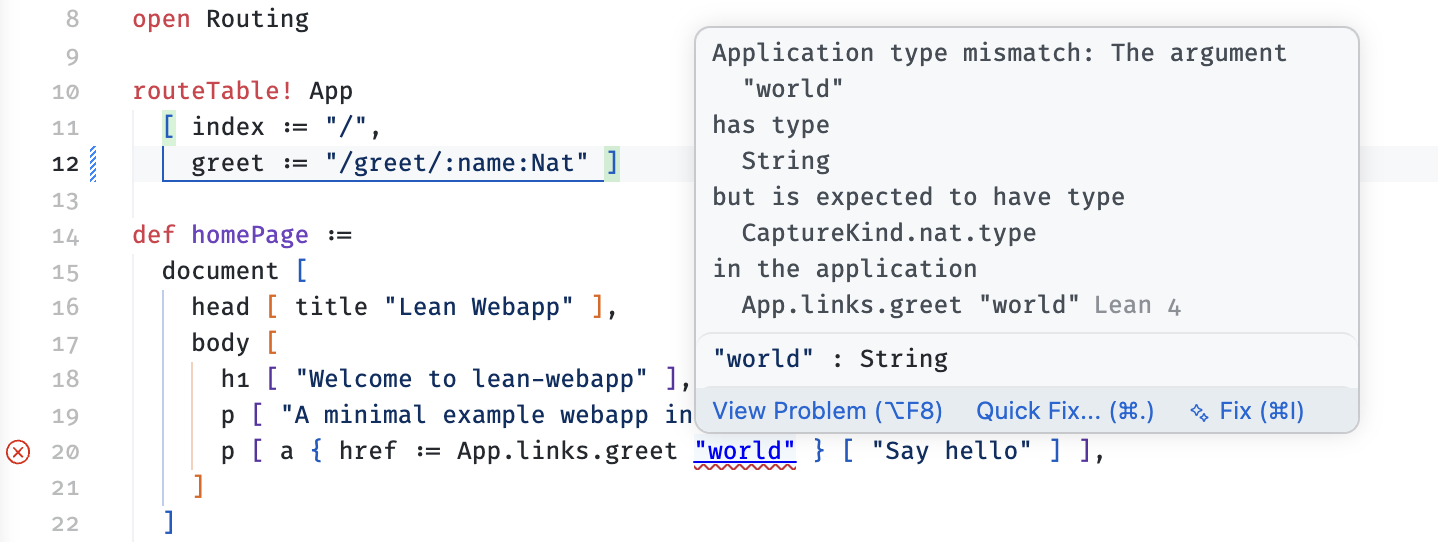
Lean's type system has worked out that generating a "greet" link with a String is (now) illegal. If you're following along, you'll see that it also flags a second error lower down the file telling us that the type of the handler function is also, now, out of sync with the route it's handling.
Both the above come as benefits of Lean's type system. But Lean also includes a theorem prover which can prove propositions about the code.
Guaranteed XSS Protection
The HTML library used by our application includes functionality to escape any text embedded within the output. We can see that this is working by putting a > character into one of the strings and using Lean's #eval command directly within the source file to see the result of the function (this is Lean's equivalent of a REPL):
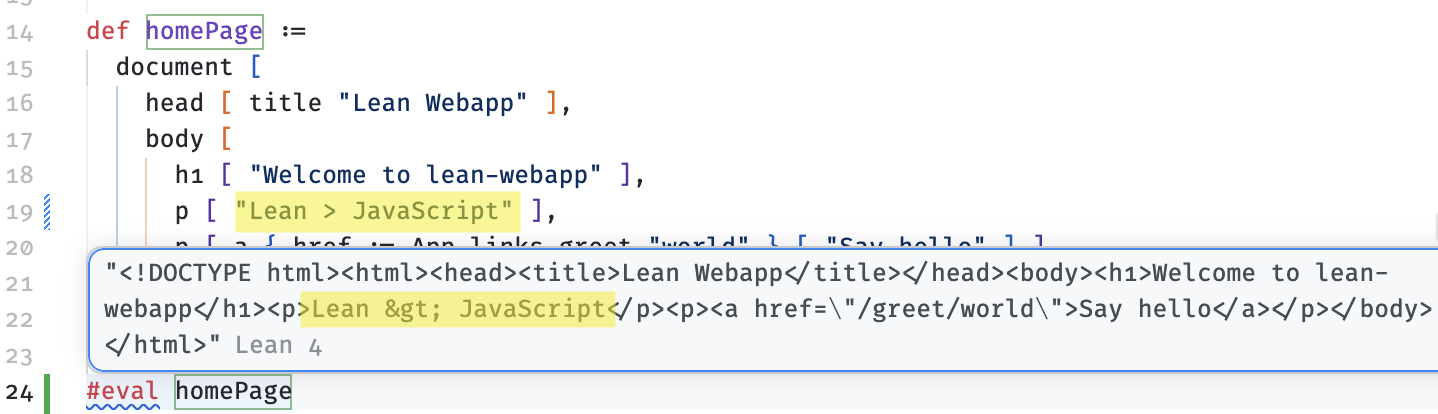
Of course, there are tests in the library confirming that this escaping does what we expect, but it goes further. It also proves a number of theorems about the code that does the escaping. Here's one of them:
theorem escape_safe (s : String) :
∀ c ∈ (escape s).toList, c ≠ '<' ∧ c ≠ '>' ∧ c ≠ '"' := _
The proposition that this theorem is proving is:
- For any string
s- For all characters
cwhich are in the result of callingescape s(escapeis the function that performs the escaping)cis not equal to<,>, or"
- For all characters
You can see the whole theorem, along with its proof, here.
In another language, we would might convince ourselves that our escaping is working by creating tests with examples (and indeed, there are some such tests in the Lean code). And that's a great approach, but it's not a guarantee. Lean allows us to go beyond testing and create code that we can rely upon because we have mathematically proven its behaviour.
The above theorem is not sufficient by itself to prove that our generated HTML isn't vulnerable, we also need to make sure that escape is used correctly within the rest of the code, but this can also be proven with similar theorems (take a look at the code to convince yourself that every loophole is covered, and let me know if you think I've missed anything).
Guaranteed Symmetric Routing
The other library used by our example is the routing library which implements routeTable!. This provides what's commonly called either "named routes" or "reverse routing" which allows a single route definition to be used both for handling incoming requests and to generate links included within generated HTML.
It's important that the forward and reverse portions of such a routing library agree with each other; we don't want to get into situations where we generate links which our router can't then handle. There have, indeed, been several cases of such bugs in high-profile web frameworks, e.g. Play, Rails. Here's a theorem within the Lean routing library which guarantees the round-trip; that parsePattern (the function that takes a string and converts it into a sequence of path segments) and renderPattern (the function that takes a sequence of path segments and returns a link) are perfect inverses of each other:
theorem parsePattern_renderPattern (segs : List PathSeg) (h : ∀ seg ∈ segs, seg.WellFormed) :
parsePattern (renderPattern segs) = some segs := _
This theorem says:
- For any list of path segments
segs:- Assuming that each segment is well formed
- Applying
parsePatternto the result of callingrenderPatternonsegsgives us back exactly the segments we started with (thesomeis there becauseparsePatternreturns anOption).
TodoMVC
As a more realistic example, here is an implementation of the popular TodoMVC web application in Lean. As well as the HTML and routing libraries we've already seen, this makes use of an HTMX library (built on top of the HTML library) and a forms library.
Next Steps
Formal validation as the new standard. Why not?
Published: 2026-07-18
Tagged: lean
Lean-ing into Software Engineering
The Lean programming language is revolutionising mathematics. More and more mathematical results have been formalised in Lean and it's increasingly becoming a standard part of the mathematician's toolbox.
Lean didn't start out as a maths tool though; it was originally created to help with software verification: proving that software was correct.
This is not a new idea: software verification was all the rage when I was doing my PhD back in the early 1990s, but it never really took off. It was just too difficult and (outside of a few safety critical projects) nobody really used it in anger.
But, in just the same way that we recently crossed a threshold meaning that it's now realistic for mathematicians to automatically verify their proofs, that same threshold is rapidly approaching for software engineering. Combined with AI-assisted software engineering, it might already have been crossed.
In this article, I'm going to show you why I think that.
tl;dr
This is quite a long article, and the code behind it is also quite long. But (and this is the whole point) that doesn't matter because it's now cheap.
In just a few minutes with Claude Code, I got not just five different implementations of an algorithm, but I also got cast-iron proofs that they work as expected and are equivalent to each other (despite taking very different approaches). Not tests which suggest that they work, but a 100% guarantee.
Today, code isn't as important as it used to be. The real value is in the machinery around the code which allows you to confirm that it's correct. As Chad Fowler says in Evaluations Are the Real Codebase:
The durable asset is the thing that lets you regenerate with confidence: evaluations that encode what the system must do, independent of how any particular implementation does it.
Tests are one way to do that, but they're far from perfect. Lean allows us to create incontrovertable mathematically verified proofs that our code is correct, and AI assisted coding allows us to do so quickly and easily.
A complicated enough problem
For this article, I'm going to use a little programming problem that I used to use when interviewing candidates. I wouldn't use it today, because AI agents have invalidated that approach to interviewing, but it's useful for our purposes because it's both simple enough to explain here, but also complicated enough to have a number of subtle pitfalls and edge cases. It can be solved in multiple different ways, each with their own tradeoffs. It's easy to state, but surprisingly difficult to get right.
We're going to create a function called partitionWhen which takes a list and a predicate (a function which takes an element of the list and returns either true or false). It partitions the list, returning a list of lists, where each sub-list starts whenever the predicate returns true.
Here's how we're going to test it:
#guard [1, 2, 0, 3, 4, 0, 5].partitionWhen (· == 0) == [[1, 2], [0, 3, 4], [0, 5]]
#guard ([] : List Nat).partitionWhen (· == 0) == []
#guard [0, 1, 2].partitionWhen (· == 0) == [[0, 1, 2]]
#guard [1, 2, 3].partitionWhen (· == 0) == [[1, 2, 3]]
#guard [0, 0, 0].partitionWhen (· == 0) == [[0], [0], [0]]
#guardis a Lean command which succeeds if the expression it's given istrueand fails if it'sfalse.- This makes it a great way to write simple tests like this.
#guardruns at compile time. So these tests will run (and succeed or fail) without having to be compiled and then run; just compiling is enough.
(· == 0)is an anonymous function with the dot "·" showing where the argument should go. This is the same asx => x === 0in JavaScript orlambda x: x == 0in Python.
Here's one way to implement partitionWhen in Lean:
def partitionWhen {α : Type _} (p : α → Bool) : List α → List (List α)
| [] => []
| [x] => [[x]]
| x :: y :: rest =>
match partitionWhen p (y :: rest) with
| g :: gs => if p y then [x] :: g :: gs else (x :: g) :: gs
| [] => [[x]]
- This is a polymorphic function which can take lists of any type
α. pis our predicate function, which takes anαand returns aBool.- Once we've given
partitionWhenits predicate, what's left is a function which takes "a list ofα(List α)" and returns "a list of lists ofα(List (List α))".
I encourage you to try implementing it in your own favourite language: it's slightly trickier than it initially seems. Here's the same approach implemented in a few other languages for comparison:
const partitionWhen = (p, xs) => {
if (xs.length === 0) return [];
if (xs.length === 1) return [[xs[0]]];
const [x, y, ...rest] = xs;
const result = partitionWhen(p, [y, ...rest]);
if (result.length === 0) return [[x]];
const [g, ...gs] = result;
return p(y) ? [[x], g, ...gs] : [[x, ...g], ...gs];
};
def partition_when(p, xs):
match xs:
case []:
return []
case [x]:
return [[x]]
case [x, y, *rest]:
match partition_when(p, [y, *rest]):
case []:
return [[x]]
case [g, *gs]:
return [[x], g, *gs] if p(y) else [[x, *g], *gs]
(defn partition-when [p xs]
(cond
(empty? xs) []
(empty? (rest xs)) [(list (first xs))]
:else
(let [[x y & more] xs
result (partition-when p (cons y more))]
(if (empty? result)
[(list x)]
(let [[g & gs] result]
(if (p y)
(cons (list x) (cons g gs))
(cons (cons x g) gs)))))))
defmodule PartitionWhen do
def partition_when(_p, []), do: []
def partition_when(_p, [x]), do: [[x]]
def partition_when(p, [x, y | rest]) do
case partition_when(p, [y | rest]) do
[g | gs] -> if p.(y), do: [[x], g | gs], else: [[x | g] | gs]
[] -> [[x]]
end
end
end
partitionWhen :: (a -> Bool) -> [a] -> [[a]]
partitionWhen _ [] = []
partitionWhen _ [x] = [[x]]
partitionWhen p (x : y : rest) =
case partitionWhen p (y : rest) of
[] -> [[x]]
(g : gs) -> if p y then [x] : g : gs else (x : g) : gs
let rec partitionWhen (p: 'a -> bool) : 'a list -> 'a list list =
function
| [] -> []
| [x] -> [[x]]
| x :: y :: rest ->
match partitionWhen p (y :: rest) with
| g :: gs -> if p y then [x] :: g :: gs else (x :: g) :: gs
| [] -> [[x]]
In just about any language other than Lean, we would now be done. We have our function, we have our tests, time to move on to the next problem.
The limitations of tests
Tests are great. The widespread adoption of automated testing is one of the best things to happen to Software Engineering over the last several decades.
But tests aren't perfect. However carefully we test, we're just checking a few examples and assuming that because our code works with them, it will work with whatever is thrown at it. How do we know that our tests have covered all the edge cases? Will partitionWhen work with any predicate? Will it works with lists of something other than natural numbers?
Sure, we can add more tests, but we have to stop somewhere. As the ISTQB says: "Testing shows the presence of defects, not their absence" and "Exhaustive testing is impossible".
Proving partitionWhen correct
Here's a theorem which, if we can find a way to prove it, will be true of any correct implementation of partitionWhen:
theorem partitionWhen_flatten {α : Type _} (p : α → Bool) :
∀ (xs : List α), (partitionWhen p xs).flatten = xs := by _
As in maths, the upside-down A "∀" means "for all". So this is saying "For any list xs of any type α, if we call partitionWhen on that list and then flatten the result, we should get our original list xs back".
Flatten takes a list of lists and turns it into a simple list by concatenating all sub-lists. So given [[1, 2], [0, 3, 4], [0, 5]] it will return [1, 2, 0, 3, 4, 0, 5]
So partitionWhen_flatten proves that no element is lost, duplicated, or reordered.
This isn't enough to guarantee that partitionWhen is correct on its own, but it is in combination with the following:
theorem partitionWhen_ne_nil_of_mem {α : Type _} (p : α → Bool) :
∀ (xs : List α), ∀ g ∈ partitionWhen p xs, g ≠ [] := by _
theorem partitionWhen_tail_false {α : Type _} (p : α → Bool) :
∀ (xs : List α), ∀ g ∈ partitionWhen p xs, ∀ z ∈ g.tail, p z = false := by _
theorem partitionWhen_head_true {α : Type _} (p : α → Bool) :
∀ (xs : List α), ∀ g ∈ (partitionWhen p xs).tail, ∀ z, g.head? = some z → p z = true := by _
In turn, these say:
- no sub-list is spuriously empty.
- sub-lists are maximal: nothing inside a sub-list (past its own head) should have split off.
- sub-lists are complete: every sub-list after the first genuinely starts at a trigger.
It's worth taking a moment to convince yourself that these theorems, taken together, guarantee that partitionWhen is doing what we expect.
So how do we go about proving that these theorems are true?
How Lean proves theorems
There is a whole book on how Lean proves theorems and I'm not going to try to cover everything it says here. But it boils down to two things:
- Lean's type system: A theorem is a proof of a proposition, and for many years we've known that (given a sufficiently powerful type system) propositions can be represented as types. This is the Curry–Howard correspondence commonly known as "propositions as types".
- Proving a proposition is exactly the same as proving that the type that represents that proposition is inhabited, which just means that we can find one example of a value of that type.
- It's really that simple: create a single value of that type and the fact that you've done so is also a proof that the proposition represented by that type is true.
- Lean's Theorem Prover: Lean provides a whole array of tactics whose entire job is finding these values.
And that's it. Find an instance of the type and you're done.
Of course, that doesn't mean that finding that instance is easy 😜.
How AI changes things
A couple of years ago, our only choice would have been to construct these proofs by hand. Lean's theorem prover is a great help, but it's still a laborious process for anything other than the simplest of proofs. So Lean would have been nothing more than an interesting footnote for most software engineers.
Today, however, AI agents are becoming very good indeed at generating proofs.
Here are complete proofs of all four of the theorems above. They run to around 160 lines of code, so I'm not going to reproduce them here. And as you can see they aren't the easiest to read or to follow. But:
- They were created entirely automatically: I did nothing beyond setting Claude Code going (and paying for the tokens 🤷).
- We don't need to understand them in depth. We just need to know that the theorems we care about are true.
In this, we're different from mathematicians. In most cases, a mathematician won't be happy with just knowing that something is true, they will also want to know why it's true. Ideally they don't just want a proof of whatever it is they're working on, they want a simple, elegant proof.
But in our case, we just want to know that the code we've written (or, more likely, that our AI agent has written on our behalf) is correct. An ugly proof that it's correct is just fine. The theorem is the important bit, the proof an implementation detail (think of it like you think of the machine code that comes out of your compiler).
There's more than one way
Our implementation of partitionWhen doesn't just work, but it provably works, which puts it ahead of 99.999% of all code ever written (which is nice). But it's not perfect.
Like most functional langauges Lean supports tail recursion meaning that recursion won't blow up the stack. But this only works if calling itself is the last thing that a function does, which isn't true of partitionWhen.
No problem, it's not too difficult to create a tail recursive version:
def partitionWhenTR {α : Type _} (p : α → Bool) (xs : List α) : List (List α) :=
go xs [] []
where
go : List α → List α → List (List α) → List (List α)
| [], cur, acc => if cur.isEmpty then acc.reverse else (cur.reverse :: acc).reverse
| x :: xs, cur, acc =>
if p x && !cur.isEmpty then
go xs [x] (cur.reverse :: acc)
else
go xs (x :: cur) acc
Or, alternatively, we can make use of the foldl function provided by the Lean standard library (some languages call this reduce):
def partitionWhenFold {α : Type _} (p : α → Bool) (xs : List α) : List (List α) :=
let (groups, cur) := xs.foldl
(fun (acc : List (List α) × List α) x =>
let (groups, cur) := acc
if p x && !cur.isEmpty then
(cur.reverse :: groups, [x])
else
(groups, x :: cur))
([], [])
(if cur.isEmpty then groups else cur.reverse :: groups).reverse
There are another couple of implementations in the GitHub repository, one using takeWhile and dropWhile, and another using span.
I'm going to assert that all the above give exactly the same result as our first implementation, but it's not immediately obvious from looking at them.
In most languages, all we could do would be to test our new implementations and hope. In Lean, we could prove the same theorems as we proved for partitionWith. But we have another choice: we can prove that these new implementations are equivalent to our first implementation.
Proving equivalence
Here's an innocent looking little theorem:
theorem partitionWhenTR_eq_partitionWhen {α : Type _} (p : α → Bool) (xs : List α) :
partitionWhenTR p xs = partitionWhen p xs := _
It literally just says "partitionWhenTR is equal to partitionWhen". Easy to say, but how on Earth do you go about proving it? In general, it's not possible for an arbitrary program (this is very closely related to the famous Halting Problem), but it is possible for two programs that are guaranteed to terminate. And one of the nice things we haven't yet mentioned about Lean is that it is able to prove whether or not a function terminates (in fact every Lean function is guaranteed to terminate unless it's marked partial)
Here are proofs that all of the different implementations are equivalent. In this case, the proofs runs to over 500 lines of code, but again, these are 500 cheap lines, automatically generated by AI.
Which means that if we have some code which uses one of our partitionWhen implementations and we decide to swap to another, we can guarantee that its behaviour will be unchanged.
Is Lean ready for production?
Lean is a full featured programming language capable of doing anything you can do in just about any other language. It's not as fast as some languages, but much faster than others (Python, we're looking at you).
What might stop you from using Lean in production is that all the focus has been on maths. Mathlib, the repository of reusable mathematical proofs is large and growing quickly; many of the things a working mathematician would expect to find are already there. The same is not true from the point of general software engineering. Reservoir, the repository of Lean packages, isn't especially well populated and a software engineer hoping to find a pre-built package which addresses their use case is likely to be disapointed. Although there are some gems in there (a formally verified regular expression engine and a zlib implementation, for example).
Also, as is obvious from this small example, each line of production code requires several lines of proof (perhaps a ratio of 1:10 or 1:20), which has cost implications (tokens at the very least).
But the benefit of knowing (not guessing, not hoping) that your code works is huge. With that in mind, I can only imagine that Lean will be of increasing importance to software engineers over time.
Notes
All the code in this article was created in VSCode configured as described here, Claude Code Pro, lean-lsp-mcp and Lean 4 Skills.
Published: 2026-07-08
Tagged: lean
Quick and Easy Clojure on AWS Lambda Part 2
This follows on from my previous article which described how to get a simple Clojure Ring application running on AWS Lambda. This article shows how to connect it to a database.
The accompanying code is here.
CloudFormation
AWS SAM provides direct support for DynamoDB, but not for more traditional databases like PostgreSQL, so that means dropping into CloudFormation. This is, sadly, rather wordy, because we'll need to configure all the neccessary AWS machinery (including setting up a VPC, security group, and database credentials) ourselves, but it's mostly standard boilerplate which is pretty well documented:
- Giving Lambda functions access to resources in an Amazon VPC.
- Creating a Secrets Manager secret for a master password.
You can see the full CloudFormation template here. We'll explain the various sections in more detail below.
VPC
To avoid having to make our database publicly visible, we're going to put both our Lambda function and database in a shared VPC. Here's how we create that VPC:
VPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: 10.0.0.0/16
We also need to define a couple of subnets (RDS requires at least two subnets, in two different avaialability zones):
Subnet1:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
CidrBlock: 10.0.1.0/24
AvailabilityZone: !Select [0, Fn::GetAZs: !Ref "AWS::Region"]
Subnet2:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
CidrBlock: 10.0.2.0/24
AvailabilityZone: !Select [1, Fn::GetAZs: !Ref "AWS::Region"]
This is using a little CloudFormation magic to select the first two availability zones in whichever region we're deploying to. You could just as easily hardcode the availability zones if you prefer.
And we need a security group which allows things within the VPC to access Postgres:
SecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: !Sub "Security group for ${AWS::StackName}"
VpcId: !Ref VPC
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: 5432
ToPort: 5432
CidrIp: !GetAtt VPC.CidrBlock
We put our Lambda function in the VPC we've created by adding the following to its Properties:
VpcConfig:
SecurityGroupIds: [!Ref SecurityGroup]
SubnetIds: [!Ref Subnet1, !Ref Subnet2]
Policies: [AWSLambdaVPCAccessExecutionRole]
Database
We now have everything we need to create a database instance:
DBSubnetGroup:
Type: AWS::RDS::DBSubnetGroup
Properties:
DBSubnetGroupDescription: !Sub "DBSubnet group for ${AWS::StackName}"
SubnetIds: [!Ref Subnet1, !Ref Subnet2]
Database:
Type: AWS::RDS::DBInstance
Properties:
DBInstanceClass: db.t4g.micro
Engine: postgres
EngineVersion: 14.15
DBName: example_lambda_app
AllocatedStorage: 20
StorageEncrypted: true
ManageMasterUserPassword: true
MasterUsername: postgres
KmsKeyId: !Ref DatabaseKey
VPCSecurityGroups: [!Ref SecurityGroup]
DBSubnetGroupName: !Ref DBSubnetGroup
Most of this is pretty obvious: we're creating an RDS database running on a db.t4g.micro instance, with 20GB of storage, encrypted at rest, and with a master user called postgres. We're adding it to the security group we created earlier, and letting it know about the subnets we created via a DBSubnetGroup.
Key Management
We've asked RDS to manage the database password for us (ManageMasterUserPassword) and store the credentials in a Secrets Manager (KMS) secret. Here's how we create that secret:
DatabaseKey:
Type: AWS::KMS::Key
Properties:
Description: DatabaseKey
EnableKeyRotation: false
KeyPolicy:
Version: 2012-10-17
Id: !Sub "key-${AWS::StackName}"
Statement:
- Effect: Allow
Principal:
AWS: !Sub "arn:${AWS::Partition}:iam::${AWS::AccountId}:root"
Action: ["kms:*"]
Resource: "*"
I've chosen to disable key rotation because I'll be passing the key to the Lambda function as an environment variable. An alternative would be to modify the Lambda function to use the Secrets Manager API to retrieve the password, but I wanted to keep the code as simple as possible. The rest is simple boilerplate taken from the article mentioned above.
To use this secret in our Lambda function, we add the following to the function's Properties:
Environment:
Variables:
DB_HOST: !GetAtt Database.Endpoint.Address
DB_PASSWORD: !Sub "{{resolve:secretsmanager:${Database.MasterUserSecret.SecretArn}:SecretString:password}}"
Deployment
Deploying is exactly the same as before: build the uberjar and then sam deploy. The first time you do this it'll take a while because it's creating the database instance, but subsequent deployments will be much quicker.
Published: 2025-01-24
Tagged: clojure